In diesem Artikel gehen wir auf die verschiedenen Arten von Machine Learning Algorithmen ein.
- Überwachtes Lernen
- Unüberwachtes Lernen
- Teilüberwachtes Lernen
- Verstärkendes Lernen
Überwachtes Lernen
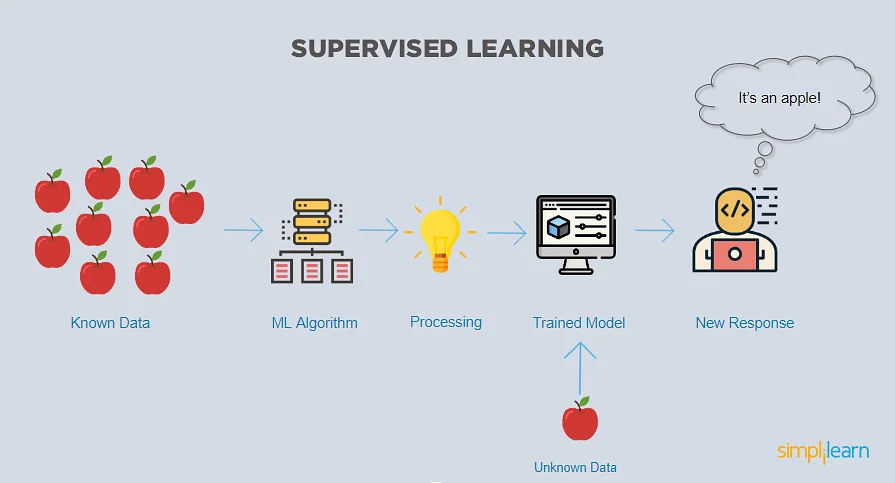 Überwachtes Lernen nutzt bekannte Daten, um daraus Zusammenhänge und Muster zu erkennen, die dann auf unbekannten Daten angewendet werden können. Dadurch werden Prognosen und Vorhersagen für die Zukunft getroffen. Die Zielvariable kann eine Klasse (bspw. Hund Ja/Nein) oder ein numerischer Wert (bspw. Umsatzprognose) sein.
Überwachtes Lernen nutzt bekannte Daten, um daraus Zusammenhänge und Muster zu erkennen, die dann auf unbekannten Daten angewendet werden können. Dadurch werden Prognosen und Vorhersagen für die Zukunft getroffen. Die Zielvariable kann eine Klasse (bspw. Hund Ja/Nein) oder ein numerischer Wert (bspw. Umsatzprognose) sein.
Einige Beispiele von überwachtem Lernen in der Praxis:
- Vorhersage von Stromverbrauch für einen Zeitraum x
- Risikobewertung von Investitionen
- Betrugserkennung
- Bilderkennung
- und noch einige mehr.
Unüberwachtes Lernen
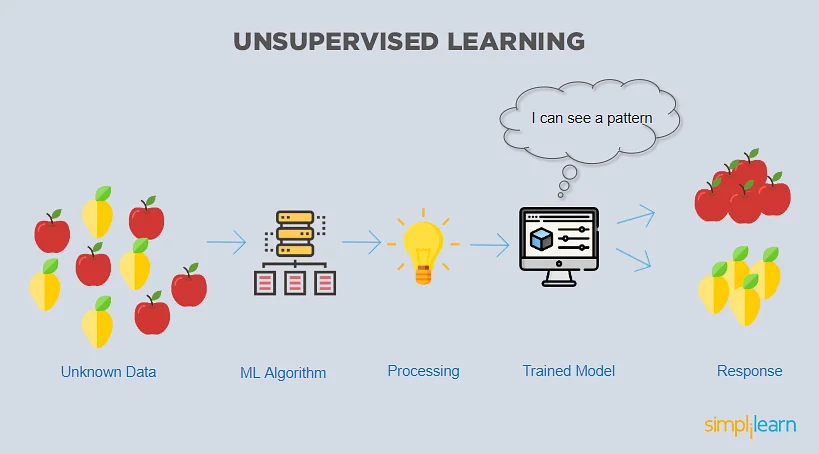
Beim unüberwachten maschinellen Lernen bekommt der Algorithmus keine Beispieldaten, sondern Daten, aus denen der Algorithmus eigenständig interessante, versteckte Gruppen und Muster erkennen soll. Der grundsätzliche Unterschied zum überwachten Lernen ist also, dass das unüberwachte Lernen nicht dafür ausgelegt ist, eine Vorhersage für eine bekannte Zielvariable (z.B. Klassifikation oder Prognose) zu berechnen.
Einige Beispiele, in denen unüberwachtes Lernen angewendet wird sind:
- Visualisierung von grossen Datenmengen
- Clusteranalysen
- Extraktion von Regeln
Teilüberwachtes Lernen
Grundsätzlich ist teilüberwachtes Lernen eine Mischung aus überwachtem und unüberwachtem Lernen. Denn es nutzt sowohl Beispieldaten mit konkreten Zielvariablen als auch unbekannte Daten.
Die Einsatzgebiete von teilüberwachtem Lernen sind im Grunde die gleichen wie bei dem überwachten Lernen.
Der Unterschied liegt darin, dass für den Lernprozess nur eine geringe Menge an Daten mit einer bekannten Zielvariable genutzt wird und eine grosse Menge an Daten, bei der diese Zielvariable noch nicht vorhanden ist. Dies hat den Vorteil, dass schon mit einer geringeren Menge von bekannten Daten trainiert werden kann. Denn oft ist die Beschaffung von bekannten Beispieldaten aufwendig und kostenintensiv, da häufig Menschen diese Daten durch manuelle Prozesse erstellen müssen.
Anwendungsbeispiele:
- Grundsätzlich die selben, wie beim überwachten Lernen
- Vor allem aber die Bilderkennung
Verstärkendes Lernen
Verstärkendes Lernen ist eine besondere Form des maschinellen Lernens. Diese Algorithmen interagieren mit der Umgebung und werden durch eine Kostenfunktion oder ein Belohnungssystem bewertet, um so selbständig eine Strategie zur Lösung des Problems zu erlernen und die Belohnung zu maximieren.
Bei verstärkendem Lernen wird dem Algorithmus nicht gezeigt, welche Aktion oder Handlung in welcher Situation die richtige ist, sondern dieser erhält durch die Kostenfunktion eine positive oder negative Rückmeldung. Also ein Feedback. Anhand der Kostenfunktion wird dann eingeschätzt, welche Aktion zu welchem Zeitpunkt, die Richtige ist. Somit lernt das System "bestärkend" durch Lob oder Bestrafung die Belohnungsfunktion zu maximieren. Der entscheidende Unterschied zu überwachtem und Unüberwachtem Lernen ist, dass das bestärkende Lernen vorab keine Beispieldaten benötigt. Der Algorithmus kann in einer Simulationsumgebung in vielen iterativen Schritten eine eigene Strategie entwickeln.
Im folgenden Video von Google DeepMind kann man dies sehr gut beobachten. Dort lernt ein KI eigenständig das Laufen.
Wenn die KI eigenständig lernen kann, dann ist kein menschliches Vorwissen mehr nötig, um komplexe Probleme zu erlernen. Und somit kommen wir auch schon zu den Anwendungen des verstärkenden Lernens. Forscher hoffen darauf, verstärktes Lernen für folgende Dinge benutzen zu können:
- Autonomes Fahren
- Entwicklung einer generellen künstlichen Intelligenz
- Autonome Robotik